Yu-Gi-Oh! Life Counter with AfterAI Flaps
When I was a kid, keeping track of Life Points (LP) in Yu-Gi-Oh! was always a hassle. This time, I decided to use AfterAI Flaps to calculate and display the Life Points for the game.
GitHub: https://github.com/AfterAILab/Yu_Gi_Oh_Life_Counter
Deployment Diagram
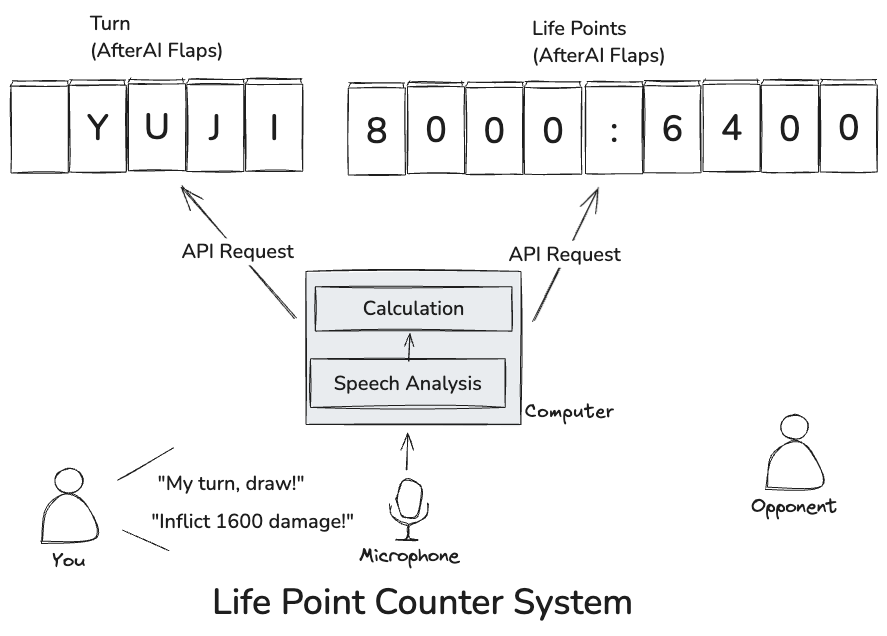
Tools Used:
- AfterAI Flaps (5 characters): Displays whose turn it is.
- AfterAI Flaps (9 characters): Displays the Life Points for both players.
- MacBook Pro (M2): My trusty MacBook for running everything smoothly.
Computer Setup
Since the MacBook Pro (M2) has plenty of computing power, I decided to run all the calculations locally. For Speech-to-Text, I used Vosk, and to extract commands from text, I initially tried using llama3.2 through Ollama. However, llama3.2 (3B) often returned incorrect results, so I ended up switching to OpenAI's gpt-4o-mini.
Flow Chart
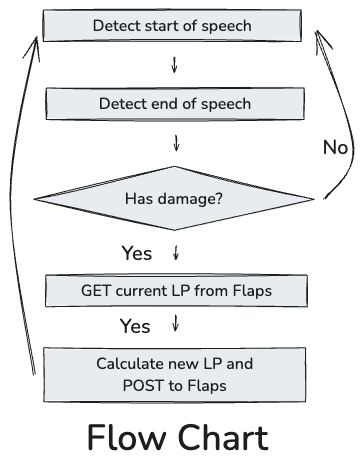
Whenever a phrase like "Inflict XXX damage to opponent" is spoken, the system retrieves the opponent's current Life Points via a GET request from the display. After calculating the damage, it updates the displayed number using a POST request.
For simplicity's sake, I didn't include the "My turn, draw!" process in the flowchart, but it follows a similar logic. You can check out the code for more details.
Prompting Issues
I initially tried having llama3.2 (3B) handle this task:
Input: Current turn and transcribed speech data.
Output: Game state changes (damage, healing, next turn, etc.).
However, llama3.2 struggled with this and often ended up healing the opponent instead of inflicting damage. I tried improving the prompt with help from other AIs, but it still didn't work as expected. In the end, I fed the same prompt to OpenAI's gpt-4o-mini, and it worked perfectly.
Conclusion
- AfterAI Flaps can be effectively used as part of a DIY project.
- Consider upgrading to version 1.2 if needed.
- Improving real-time performance: It might help to interrupt mid-speech rather than waiting for speech completion events from the voice engine.
- If you can adjust the delay before these events occur via engine parameters, that would be ideal.
- Model performance varies significantly: Even for small tasks like this one.
- While llama is a well-known model, its struggle with this task was unexpected.
- There are versions of llama3.2 with more parameters than 3B; perhaps those would perform better.
- I couldn't find any information on the exact number of parameters for gpt-4o-mini after searching online.